Retrieval Chatbot
An FAQ Chatbot to help answer queries in real time using NLP. Devised supervised learning model to predict the category of the question asked and used similarity matrix to find a question closest to the one asked by the customer.

Business Problem
This is a simple Q&A Chatbot designed to answer frequently asked questions by customers, without them having to wait to speak to a bank’s customer representative. A well-defined FAQ chatbot improves your customers’ journey multifold. Being able to ask questions in a conversational manner provides a better experience to your customers and prospects—and elevates your brand’s image. It is quick and efficient.
Roadmap
- Load and Inspect Data
- Tokenize words, stemming, TF-IDF Vectorization
- Unigram and Bigram Correlations
- Model fitting for prediction
- Model Validation
- Cosine similarity for similar questions
- Start Chatting!
Load Data
Our corpus consists of 1764 questions from 7 different categories namely security, accounts,cards, fundstransfer,insurance,investments and loans. Fundstransfer has the least amount of questions.
Imbalanced Dataset
We have certain categories with more questions than the others but in our case the majority classes might be of our great interest as people tend to ask a lot of questions from that category.It is desirable to have a classifier that gives high prediction accuracy over the majority class, while maintaining reasonable accuracy for the minority classes. Therefore, we will leave it as it is.
data = pd.read_csv('bankfaq.csv')
data.head(3)
| Question | Answer | Class | |
|---|---|---|---|
| 0 | Do I need to enter ‘#’ after keying in my Card... | Please listen to the recorded message and foll... | security |
| 1 | What details are required when I want to perfo... | To perform a secure IVR transaction, you will ... | security |
| 2 | How should I get the IVR Password if I hold a... | An IVR password can be requested only from the... | security |
Number of observations and columns: (1764, 3)
Number of unique categories: 7
| Question | Answer | |
|---|---|---|
| Class | ||
| accounts | 306 | 306 |
| cards | 403 | 403 |
| fundstransfer | 14 | 14 |
| insurance | 469 | 469 |
| investments | 140 | 140 |
| loans | 375 | 375 |
| security | 57 | 57 |
Missing Values
Question 0
Answer 0
Class 0
dtype: int64
NLP Text Processing Pipeline
NLTK Tokenization
The process of converting text contained in paragraphs or sentences into individual words (called tokens) is known as tokenization. With any typical NLP task, one of the first steps is to tokenize your pieces of text into its individual words/tokens, the result of which is used to create so-called vocabularies that will be used in the langauge model we plan to build. We’ll create an instance of RegexpTokenizer to extract the stream of tokens with the help of regular expressions. This will automatically remove punctuations, white spaces, gaps and any special characters.
Stemming and Lemmitization
Lemmatization is the process where we take individual tokens from a sentence and we try to reduce them to their base form. The process that makes this possible is having a vocabulary and performing morphological analysis to remove inflectional endings. The output of the lemmatization process is the lemma or the base form of the word.
Stemming is just a simpler version of lemmatization where we are interested in stripping the suffix at the end of the word. When stemming we are interested in reducing the inflected or derived word to it’s base form.
The difference is that stem might not be an actual word whereas, lemma is an actual language word. Stemming follows an algorithm with steps to perform on the words which makes it faster. Whereas, in lemmatization, you used WordNet corpus and a corpus for stop words as well to produce lemma which makes it slower than stemming.
Scoring words with TF-IDF
Term Frequency (TF) The number of times a word appears in a document divded by the total number of words in the document. Every document has its own term frequency.
Inverse Data Frequency (IDF) The log of the number of documents divided by the number of documents that contain the word w. Inverse data frequency determines the weight of rare words across all documents in the corpus.
Lastly, the TF-IDF is simply the TF multiplied by IDF.
Questions before cleaning
array(['Do I need to enter ‘#’ after keying in my Card number/ Card expiry date/ CVV number',
'What details are required when I want to perform a secure IVR transaction',
'How should I get the IVR Password if I hold an add-on card', ...,
'What options should I choose to withdraw cash from the ATM',
'What should I do and whom to contact if my card is lost',
'Are there extra charges to be aware of'], dtype=object)
Questions after cleaning
['Do I need enter key Card number Card expiry date CVV number',
'What detail require I want perform secure IVR transaction',
'How I get IVR Password I hold add card',
'How I register Mobile number IVR Password',
'How I obtain IVR Password']
We will use sklearn.feature_extraction.text.TfidfVectorizer to calculate a tf-idf vector:
- sublinear_df is set to True to use a logarithmic form for frequency.
- min_df is the minimum numbers of documents a word must be present in to be kept.
- norm is set to l2, to ensure all our feature vectors have a euclidian norm of 1.
- ngram_range is set to (1, 2) to indicate that we want to consider both unigrams and bigrams.
- stop_words is set to “english”
We have 1764 questions and 4061 features after TF-IDF vectorization
(1764, 4061)
Label encoding target class
It can be used to transform non-numerical labels to numerical labels.
We have 7 different categories numbered from 0-6.
[0 1 2 3 4 5 6]
Model Building
We are using 25% for testing and 75% for training
Number of samples in training set: 1323
Number of samples in test set: 441
Number of examples from each category in the test set
2 4
6 15
4 44
0 80
1 81
5 95
3 122
dtype: int64
Model Building and Evaluation
We will build and evaluate 3 models namely Multi-Class Logistic Regression, LinearSVC and Multinomial Naive bayes.
Logistic Regression
Measures relationship between categorical dependent variable and one or more independent variable by estimating probabilities using sigmoid function. Multi class logistic regression will fit 7 binary classification models.Each classifier is trained to determine whether or not an example is part of class or not. To predict the class for a new example,we run all classifiers and choose the class with the highest score.
LinearSVC
LinearSVC uses one-vs-rest approach for multi class classification so it will fit 7 models since we have 7 classes. It uses liblinear estimator that converges faster than the SVC with linear kernal. We will tune the regularization parameter.
Multinomial Naive Bayes
Naive Bayes is a family of algorithms based on applying Bayes theorem with a strong(naive) assumption, that every feature is independent of the others, in order to predict the category of a given sample. They are probabilistic classifiers, therefore will calculate the probability of each category using Bayes theorem, and the category with the highest probability will be output. The multinomial Naive Bayes classifier is suitable for classification with discrete features (e.g., word counts for text classification). The multinomial distribution normally requires integer feature counts. However, in practice, fractional counts such as tf-idf may also work. If a categorical predictor is not observed in the training dataset, model will assign zero as the probability. This is corrected using “Laplace smoothing” which is alpha parameter.
Logistic Regression Classification Report
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=1000,
multi_class='ovr', n_jobs=None, penalty='l2',
random_state=None, solver='liblinear', tol=0.0001, verbose=0,
warm_start=False)
precision recall f1-score support
0 0.91 0.90 0.91 80
1 0.90 0.95 0.92 81
2 0.00 0.00 0.00 4
3 0.75 1.00 0.86 122
4 1.00 0.50 0.67 44
5 0.99 0.88 0.93 95
6 1.00 0.47 0.64 15
accuracy 0.87 441
macro avg 0.79 0.67 0.70 441
weighted avg 0.88 0.87 0.86 441
Logistic Regression Accuracy: 0.8707482993197279
LinearSVC Classification Report
We will evaluate accuracy for different regularization parameters and we are using one vs rest classification technique
0.2
LinearSVC: 0.9183673469387755
0.4
LinearSVC: 0.9342403628117913
0.6
LinearSVC: 0.9387755102040817
0.8
LinearSVC: 0.9365079365079365
1
LinearSVC: 0.9387755102040817
precision recall f1-score support
0 0.95 0.96 0.96 80
1 0.93 0.96 0.95 81
2 1.00 0.75 0.86 4
3 0.91 0.99 0.95 122
4 1.00 0.77 0.87 44
5 0.98 0.95 0.96 95
6 0.79 0.73 0.76 15
accuracy 0.94 441
macro avg 0.94 0.87 0.90 441
weighted avg 0.94 0.94 0.94 441
Multinomial Naive bayes Classification Report
precision recall f1-score support
0 0.91 0.91 0.91 80
1 0.78 0.99 0.87 81
2 0.00 0.00 0.00 4
3 0.82 0.99 0.90 122
4 1.00 0.20 0.34 44
5 0.90 0.91 0.90 95
6 1.00 0.40 0.57 15
accuracy 0.85 441
macro avg 0.77 0.63 0.64 441
weighted avg 0.86 0.85 0.82 441
0.8503401360544217
Model Evaluation using 5-fold cross validation.
In a K-fold Cross Validation, the following procedure is followed: Model is trained using K-1 of the folds as training data Resulting Model is validated on the remaining data This process is repeated K times and performance measure such as “Accuracy” is computed at each step.
model_name fold_idx accuracy
0 LinearSVC 0 0.903683
1 LinearSVC 1 0.872521
2 LinearSVC 2 0.844193
3 LinearSVC 3 0.926346
4 LinearSVC 4 0.863636
5 MultinomialNB 0 0.838527
6 MultinomialNB 1 0.824363
7 MultinomialNB 2 0.779037
8 MultinomialNB 3 0.841360
9 MultinomialNB 4 0.818182
10 LogisticRegression 0 0.852691
11 LogisticRegression 1 0.830028
12 LogisticRegression 2 0.784703
13 LogisticRegression 3 0.827195
14 LogisticRegression 4 0.832386
A boxplot of the models by accuracies reveal that LinearSVC is performing better than Naive bayes and Logistic Regression
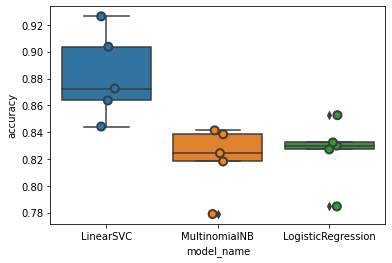
Mean accuracy for all 3 models:
model_name
LinearSVC 0.882076
LogisticRegression 0.825401
MultinomialNB 0.820294
Name: accuracy, dtype: float64
LinearSVC performs much better than Naive bayes and Logistic Regression.
Misclassification Rate
Now we will look at the categories which were misclassified by the model. For this we will use confusion matrix.
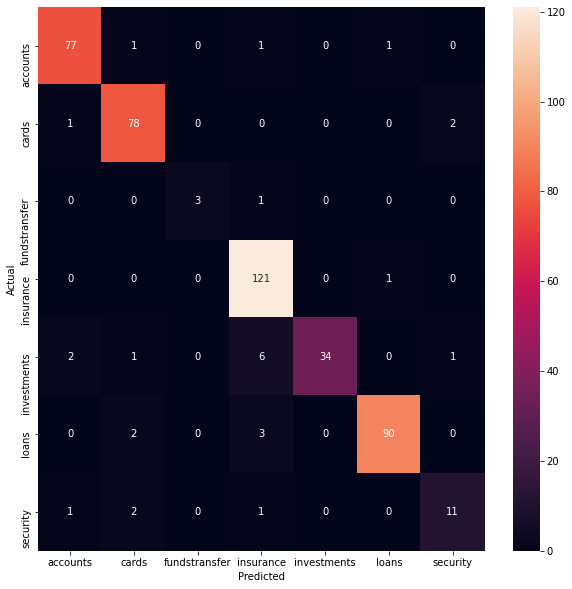
We can observe that a lot of the questions from insurance category were misclassified as investments. We can dig deeper to see which investment questions were classified as insurance.
Actual class investments predicted as insurance
1256 How will I receive the Dividend Pay amount
1344 What are the benefits of InvestTrack
1293 What happens when the issue fails/is withdrawn
1234 What are the advantages of investing in SIP
1250 Why should I invest in SIP's right now
1255 How will I receive the redemption amount
Name: Question, dtype: object
Cosine Similarity
Once, we have identified which category the question belongs to, we will then apply cosine similarity to find the question that best matches the query asked by the user. The answer related to that question is then provided by the bot.
Cosine similarity is generally used as a metric for measuring distance when the magnitude of the vectors does not matter. This happens for example when working with text data represented by word counts. We could assume that when a word (e.g. science) occurs more frequent in document 1 than it does in document 2, that document 1 is more related to the topic of science. However, it could also be the case that we are working with documents of uneven lengths (Wikipedia articles for example). Then, science probably occurred more in document 1 just because it was way longer than document 2. Cosine similarity corrects for this.
Chat Function
- TYPE "TOP5" to Display 5 most relevent results
- TYPE "CONF" to Display the most confident result
- TYPE "STOP" to Stop Debugging statements.
- Press Q to Quit
chat()
Bot: Welcome to the bank!
Press Q to Quit
TYPE "DEBUG" to Display Debugging statements.
TYPE "STOP" to Stop Debugging statements.
TYPE "TOP5" to Display 5 most relevent results
TYPE "CONF" to Display the most confident result
You: CONF
Bot: I will display the most relevant answer.
You: What is a Personal Assurance Message or Personal Greeting
Assuming you asked: What is a Personal Assurance Message or Personal Greeting
Bot: When you register for Verified by Visa/ MasterCard SecureCode, you are asked to create a Personal Assurance Message/ Personal Greeting. So when you pay online, always look for your Personal Assurance Message/ Personal Message to ensure that HDFC Bank is authenticating you. View more
Bot: Was this answer helpful? Yes/NoNo
Bot: Would you like me to suggest you questions? Yes/No Yes
1 Question: What is a Personal Assurance Message or Personal Greeting
-
2 Question: I don't see my Personal Assurance Message on the Secure page . What should I do
-
3 Question: Can I set my Personal Assurance Message to be the same as my VBV / MSC Password
-
4 Question: While trying to register I am getting error message Card already enrolled , what should I do
-
5 Question: While trying to register my card, I am getting the error message stating mobile no. mismatch, what could be the reason
-
Please input the question number you find most relevant: 4
Question: While trying to register I am getting error message Card already enrolled , what should I do
Answer: Your card is already registered for Verified by Visa / MasterCard SecureCode, you don't have to re-register your card. In case you don't remember your password, please click on forgot password on the Netsafe login page or on the secure page while transacting and you can reset your password.
You: TOP5
Bot: I will display Top 5 relevant answers.
You: Can I register more than one HDFC Bank Credit/ Debit Card
Question: What should I do if my Debit Card is not working
Answer: If there is a technical problem because of which your card is not working, we request you to contact us on our Phone Banking center or branch and hotlist/block the said card. Please make a request to issue a new card for your account which will be free of cost and should be delivered to you in 7 working days time once issued. For more details on PhoneBanking numbers and their timings, click here. For a comprehensive list of branches, click here. View more
--------------------------------------------------
Question: Are there transaction limits for Debit Card
Answer: A daily ATM limit of Rs. 25,000 for withdrawals, and Rs. 1,25,000 at merchant establishments .
--------------------------------------------------
Question: Are there charges I should know about HDFC Bank Rewards Debit Card
Answer: Another benefit of the Rewards Debit card is that there are absolutely no transaction charges when shopping at a merchant location.
--------------------------------------------------
Question: Are there transaction limits for Platinum Debit Card
Answer: Depending on the balance in your account, it is possible to withdraw up to Rs. 1 lakh at the ATM daily, and spend Rs. 2.75 lacs daily. These limits have been set for your card security.
--------------------------------------------------
Question: What is the HDFC Bank ForexPlus card
Answer: HDFC Bank ForexPlus card is a magnetic strip based prepaid card introduced in partnership with Visa / Mastercard International. The card offers you a convenient and secure way to carry forex. This card offers you the freedom to shop anywhere in the world and provides access to the currency of your destination at competitive market rates. It can be used at all Visa / Mastercard ATMs and Merchant establishment worldwide. This card cannot be used for making payments in India, Nepal or Bhutan.
--------------------------------------------------
Bot: Was this answer helpful? Yes/NoYes
Bot: It was good to be of help.